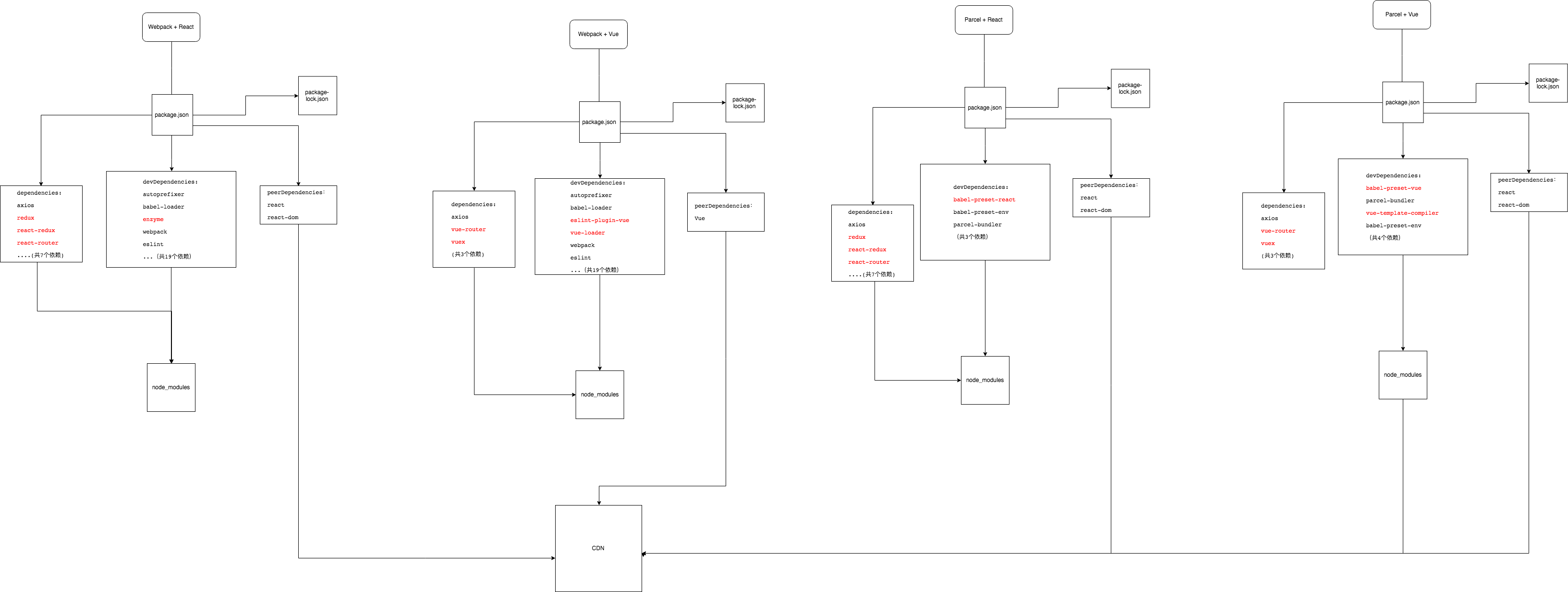
<body> <button id="test">属性事件</button> </body> <script> var test = document.getElementById('test'); test.onclick = hello;
test.onclick = world;
test.onclick = helloWolrd;
function hello() { console.log('hello'); } // world 会覆盖 world function world() { console.log('world'); } // 必须放一个fp function helloWolrd() { console.log('hello'); console.log('world'); } </script>
(3) 事件监听回调 (dom2)
注意事件类型没有on
1 2 3 4 5 6 7 8 9 10 11 12
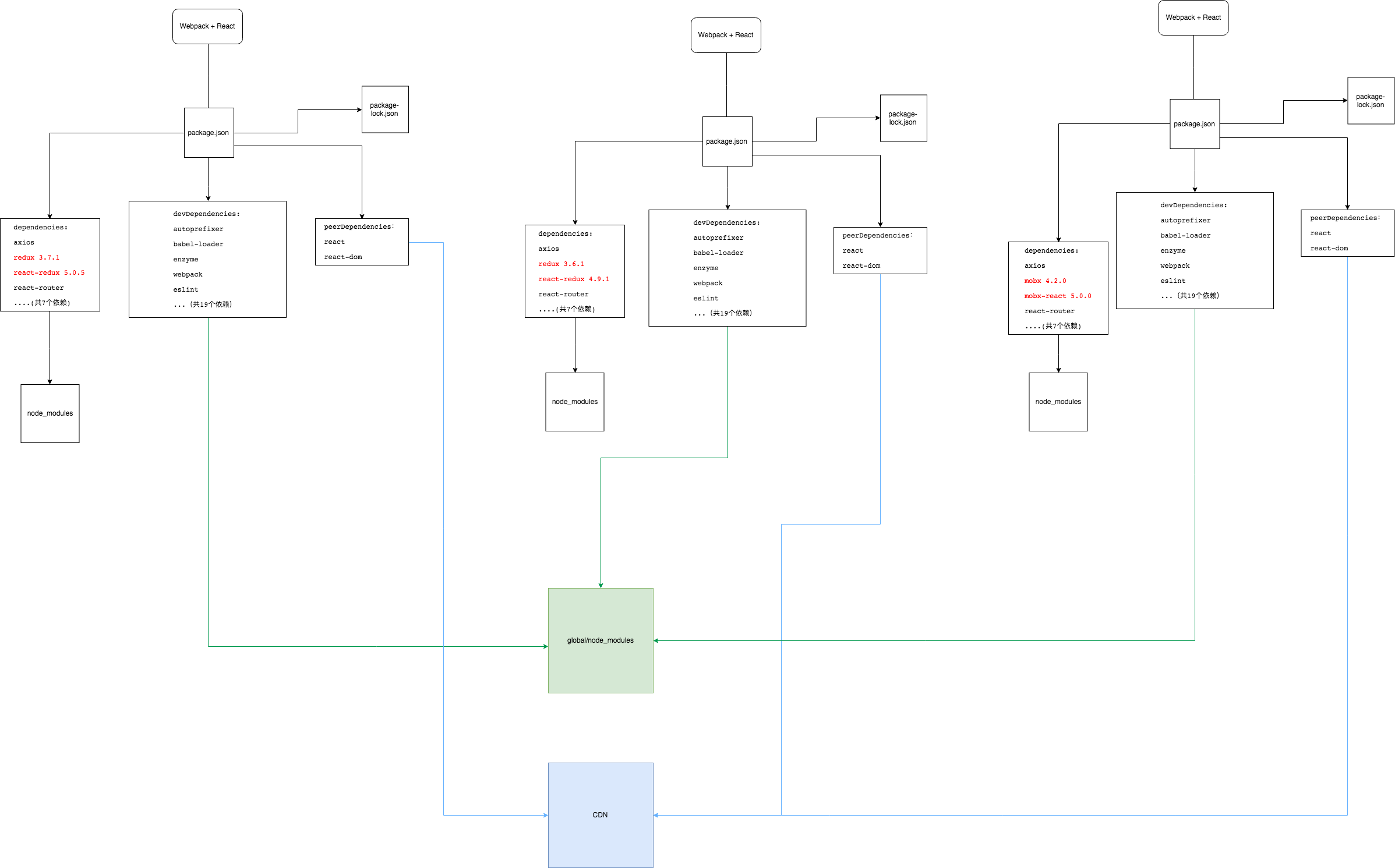
<body> <buttonid="test">属性事件</button> </body> <script> var test = document.getElementById('test'); functiongetEvent(e) { console.log(e); } test.addEventListener('click',getEvent); </script>
</body> <script> var btn = document.getElementById('button'); btn.addEventListener('click',clickEvent,false); btn.addEventListener('click',clickEvent,true); function removeCaptureEvent(){ btn.removeEventListener('click',clickEvent,true); console.log('removeCaptureEvent ') } function removeBubbleEvent(){ btn.removeEventListener('click',clickEvent,false); console.log('removeBubbleEvent ') } function clickEvent(){ console.log('clickEvent'); } </script>
删除的函数,必须与添加时函数同一引用
1 2 3 4 5 6
var div = document.getElementById('div'); var listener = function (event) { /* do something here */ }; div.addEventListener('click', listener, false); div.removeEventListener('click', listener, false);
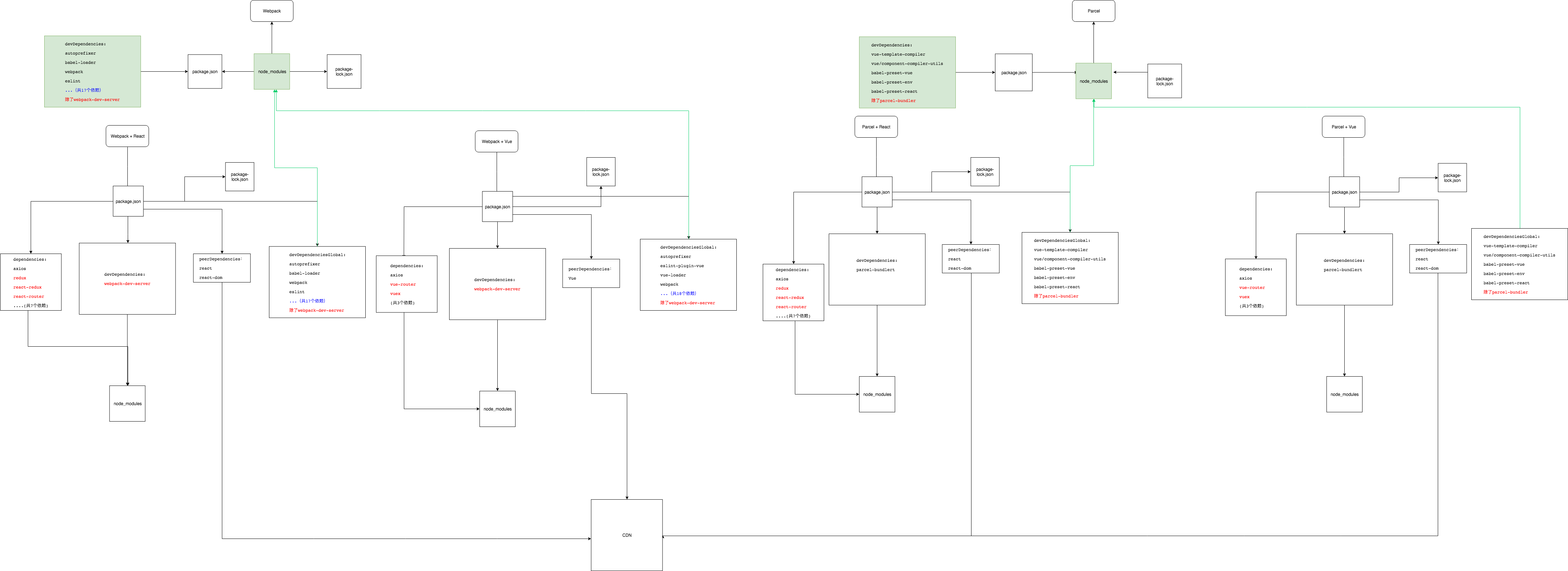
if (isUpdate) { console.log(`will install in ${execPath}`); console.log('start install public package for neo-antd'); console.log('please wait some minutes.....');
exec(script, function (err, stdout, stderr) { console.log(stdout); if (err) { console.log('error:' + stderr); } else { console.log(stdout); console.log('package init success'); console.log(`The global install in ${execPath}`); } });
} else { console.log('not any update'); console.log('will be run next'); }
The md5 for this project: 4c4ee67828b3e09f07b17774cb1633c7 init global modules... will install in /Users/neo/home/webpack start install public package for neo-antd please wait some minutes....
....
added 704 packages in 7.777s
package init success The global install in /Users/neo/home/webpack
[fsevents] Success: "/Users/neo/home/webpack/npm-module-share/node_modules/fsevents/lib/binding/Release/node-v57-darwin-x64/fse.node" already installed Pass --update-binary to reinstall or --build-from-source to recompile npm WARN npm-module-share@1.0.0 No description
The md5 for this project: 4c4ee67828b3e09f07b17774cb1633c7 will check update not any update will be run next npm WARN npm-module-share@1.0.0 No description
update in 1.291s
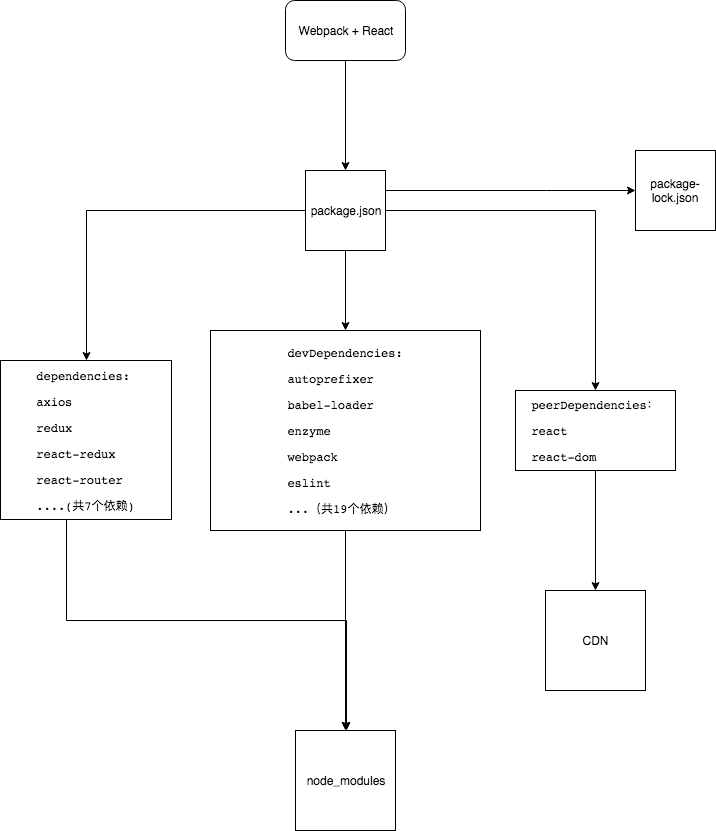
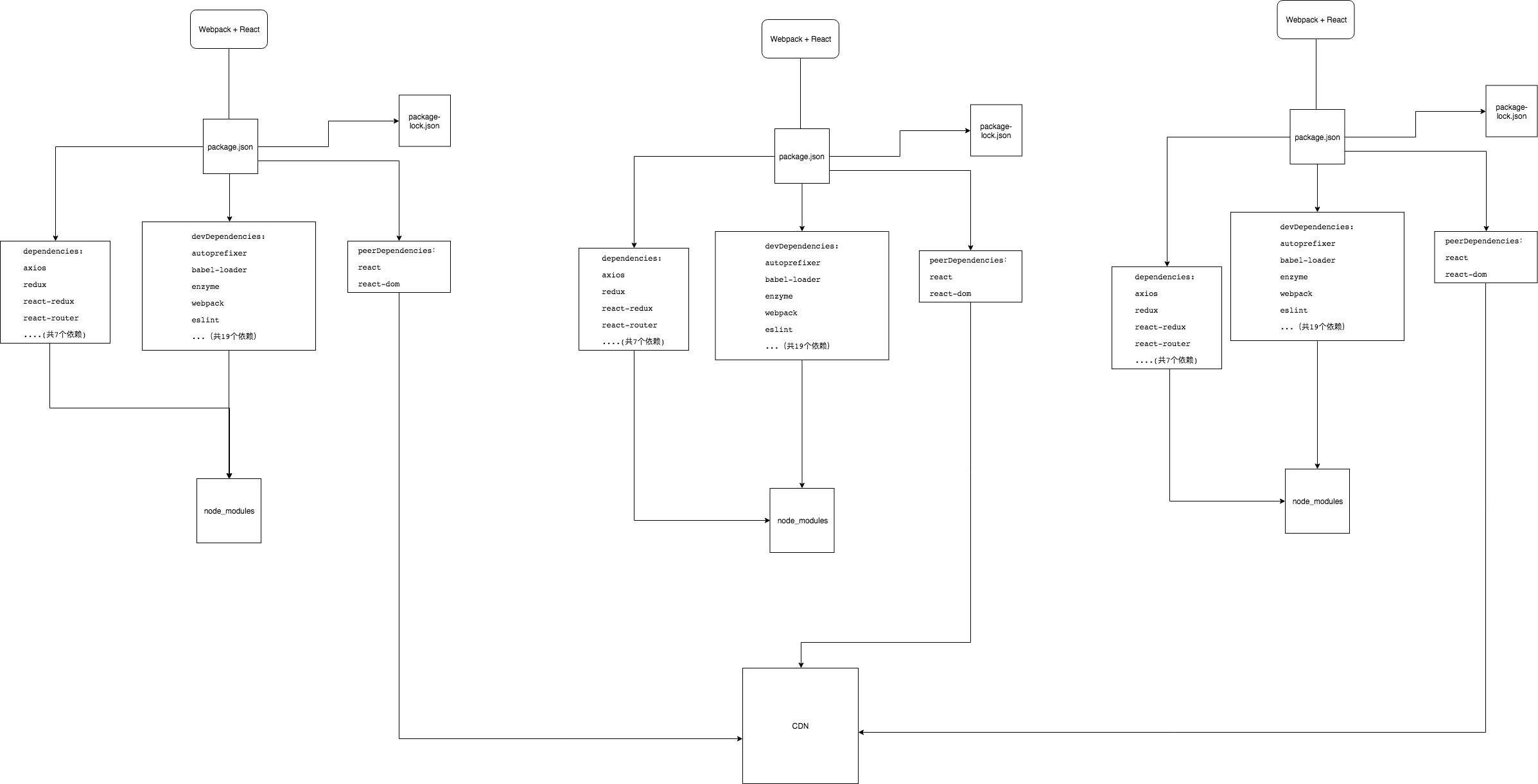
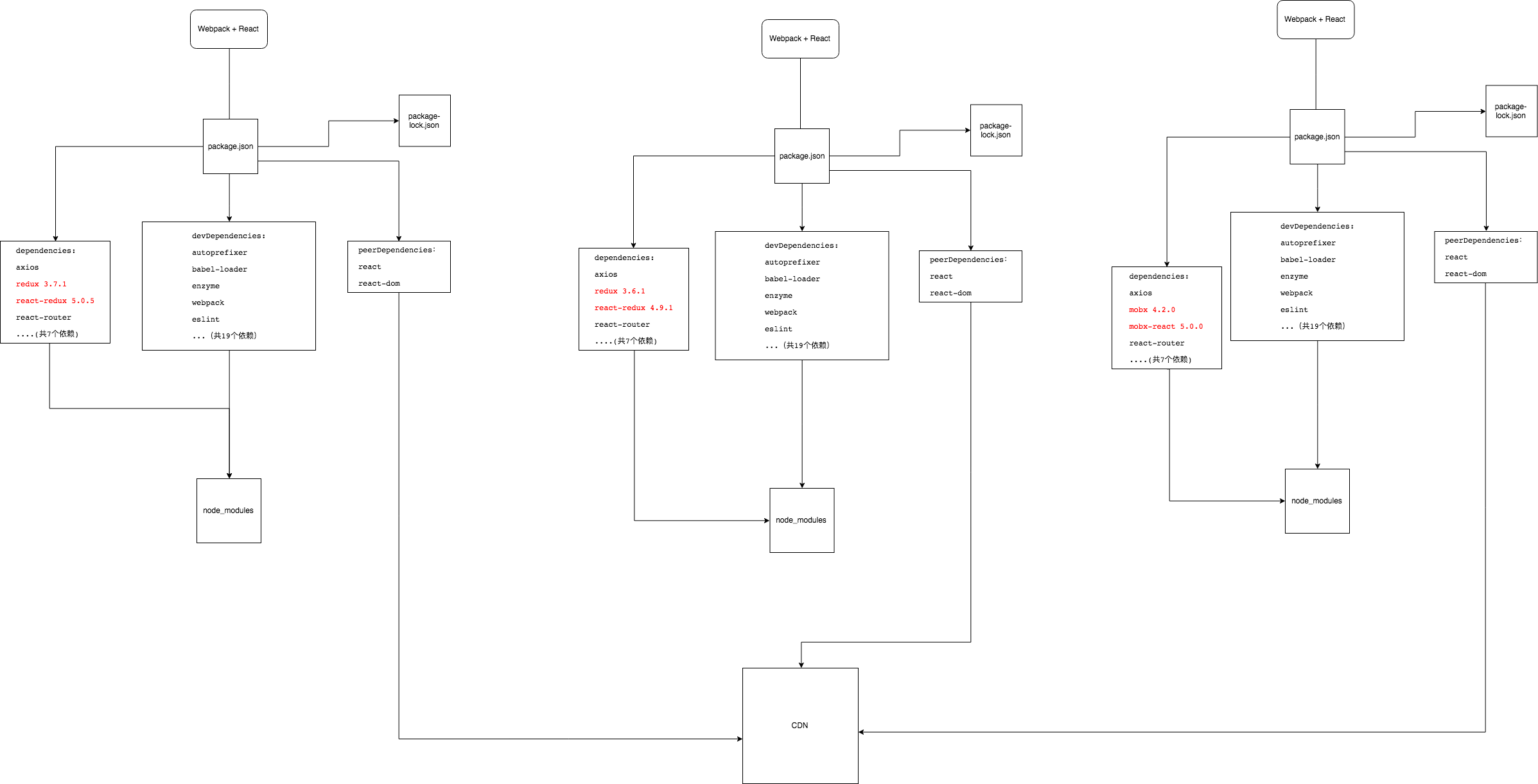
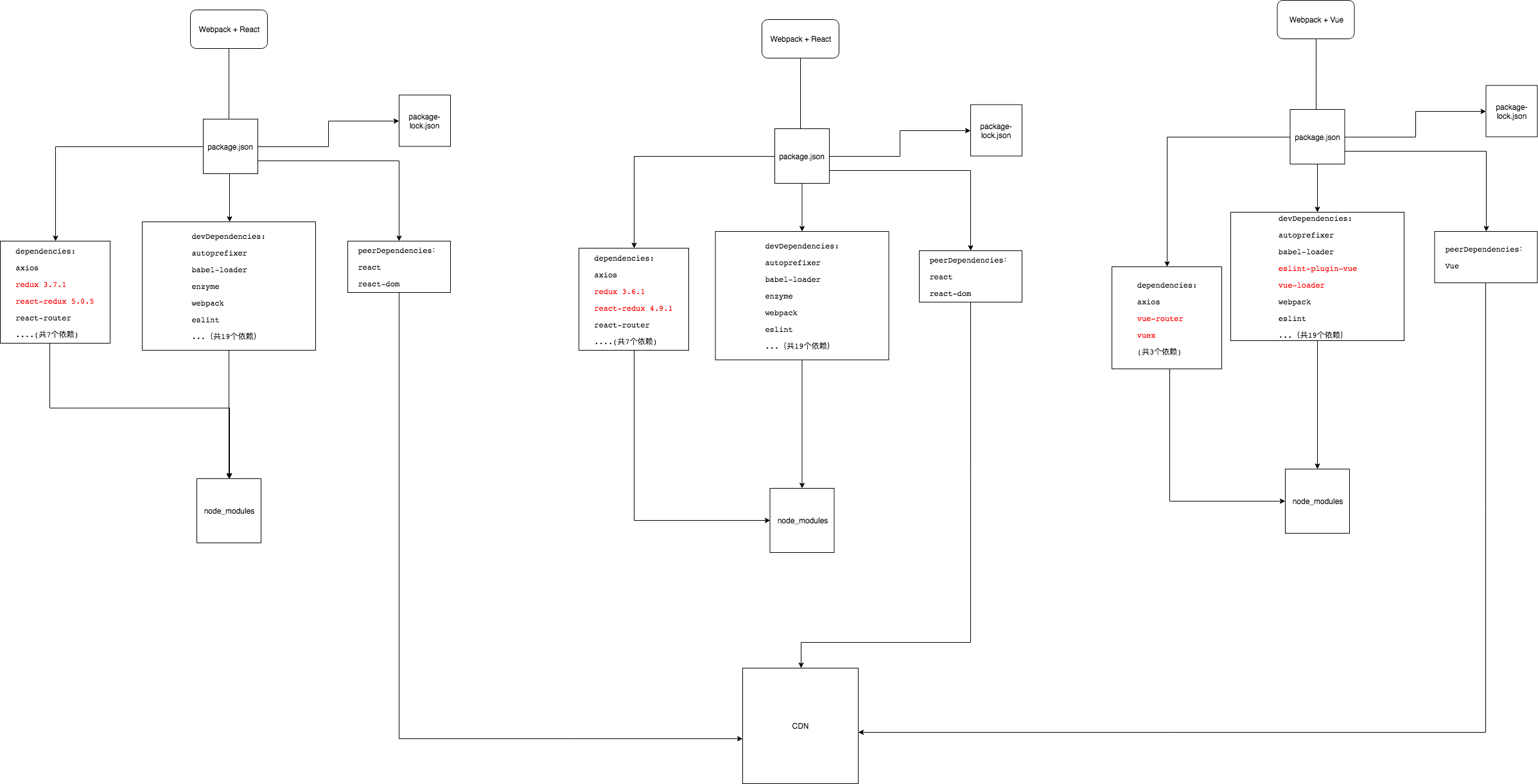
(6) 几点需要注意的地方
a. npm script中直接需要调用的模块,需要放置到该项目的dependencies和devDependencies中
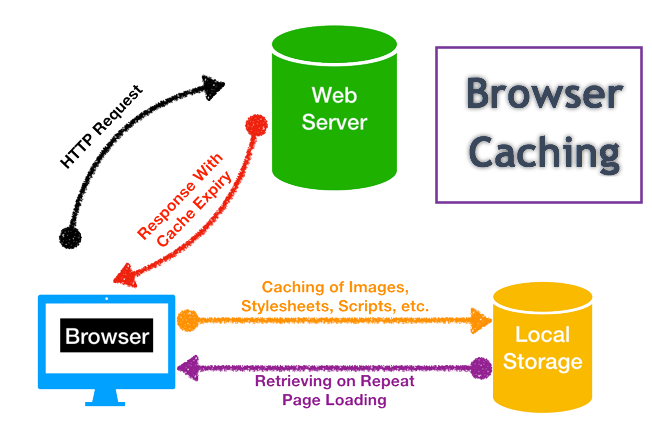
// exit if the browser implements that event if ( "onhashchange"inwindow.document.body ) { return; }
var location = window.location, oldURL = location.href, oldHash = location.hash;
// check the location hash on a 100ms interval setInterval(function() { var newURL = location.href, newHash = location.hash;
// if the hash has changed and a handler has been bound... if ( newHash != oldHash && typeofwindow.onhashchange === "function" ) { // execute the handler window.onhashchange({ type: "hashchange", oldURL: oldURL, newURL: newURL });